Blog Onyme
Quelques notions en analyse syntaxique15 mai 2011L’analyse syntaxique est un domaine de la linguistique assez riche et souvent confus. A partir d’un besoin de clarte en matiere d’analyseurs syntaxiques et morphosyntaxiques, l’idee est venue de faire ce point, probablement non-exhaustif, sur la terminologie du domaine theorique et applicatif de la syntaxe. La notion de syntaxe qui suit ne releve (a nouveau) pas du domaine purement informatique mais decoule directement de la linguistique. Ce billet s’adresse a des lecteurs relativement avertis, avec deja quelques connaissances linguistiques et talistiques. Il s’agit ici de decrypter un probleme en traitement automatique du langage naturel, a savoir ce qu’est et ce qu’on peut attendre (en theorie) d’une analyse syntaxique automatisee sur corpus. De maniere generale, l’objectif de l’analyse syntaxique est double en TAL :
Les theories linguistiques sont nombreuses en matiere d’analyse syntaxique ou differentes ecoles et formalismes se cotoient. Un autre billet de ce blog approche la syntaxe du point de vue de la grammaire formelle et des differents types d’algorithmes existants. Nous aborderons ici les autres notions de tagging, parsing ou chunking, d’analyse syntaxique de surface ou profonde et enfin de grammaires de constituants ou de dependances. Tagging, parsing et chunkingTaggingLe tagging, plus communement appele analyse morphosyntaxique, gere, apres une etape de segmentation d’un texte (decoupage de la chaine de caracteres en unites pertinentes de types paragraphe, mot, verbatim, phrase, etc.), l’attribution d’etiquettes aux unites lexicales (c’est-a-dire aux termes des phrases). Ces unites peuvent etre simples ou complexes. Ce module se scinde en plusieurs phases dont quatre principales : segmentation, detection, desambiguisation et etiquettage. Par ailleurs, il appose deux types d’etiquettes aux unites du texte :
L’etiqueteur le plus connu et le plus utilise, du fait de sa gratuite et de ses performances, est le TreeTagger. Un autre billet de ce blog a deja ete consacre a ce sujet. Un tel outil presente l’interet de pouvoir extraire des donnees a un niveau superieur de la simple chaine de caracteres. Connaitre l’organisation syntaxique d’une phrase permet d’en extraire et d’en comprendre plus pertinemment les informations qu’elle contient. Souvent cumulee a une lemmatisation qui associe a chaque terme du texte sa forme canonique, le systeme de traitement automatique peut proceder a une analyse affinee a partir de regles grammaticales (appelees grammaires formelles). Ainsi, par la lemmatisation, il est possible d’associer les formes conjuguees a leur imperatif correspondant, forme canonique : marchais, marche, marchaient deviennent marcher ; par l’analyse syntaxique il est possible d’associer la bonne forme canonique et d’etablir des regles de desambiguisation : selon sa position dans la phrase, marche sera considere comme une forme verbale de marcher ou comme un nom commun. C’est ensuite a l’analyse semantique de les rapprocher. Parsing et chunkingLes parsing et chunking, relevants quant a eux de l’analyse syntaxique, aboutissent a une representation de la structure d’une phrase a partir de l’exploitation des etiquettes morphosyntaxiques obtenues lors du tagging. Parsing et chunking se differencient par le fait que le second n’offre qu’une analyse syntaxique dite “legere” de la phrase ou tous les constituants ne sont pas identifies. Par comparaison au precedant tagging, le parsing ou chunking permettent une representation plus complexe de la phrase et donc une plus grande finesse dans l’analyse pour des regles plus poussees. La traduction automatique, par exemple, favorisera ce type de traitement pour mieux gerer les ambiguites. Les analyseurs souvent cites pour exemples et traitant le francais sont le MaltParser ou encore le MSTParser qui fournissent des arbres de dependances apres entrainement (statistiques) sur corpus arbores mais qui n’ont pas d’analyseur morpho-syntaxique integre. Nous y revenons par la suite. Un autre usage d’un analyseur syntaxique est visible sous le site du LATL pour un apprentissage ludique (! et tout en couleur) de la syntaxe. Analyse syntaxique profonde ou de surfaceRelative a la Theorie du gouvernement et du liage de Noam Chomsky, l’analyse syntaxique de surface represente la structure de la phrase telle qu’elle est, dans sa linearite. Elle est donc dependante de la langue dans laquelle l’enonce est exprime (SVO : sujet-verbe-objet en francais, SOV : sujet-objet-verbe en latin, etc.). L’analyse syntaxique profonde represente la structure d’une phrase selon un schema syntaxique universel ou des universaux de langage. Une relation d’un a plusieurs existe entre ces deux representations : les nombreux types de langues existants font qu’il y a plusieurs representations en surface d’une meme phrase pour une representation unique en syntaxe profonde. Pour resumer :
Une analyse par constituants ou par dependances n’est donc pas a confondre avec cette notion et peut representer soit la structure lineaire, soit la structure profonde de la phrase. Grammaire de constituants et grammaire de dependancesLes deux types de grammaires font partie de la classe des grammaires symboliques, opposees aux grammaires statistiques, et sont basees sur des theories du XXᵉ siecle. Grammaire de constituants et grammaire de dependances sont relatives a deux approches de la syntaxe. Souvent opposees, elles le sont de moins en moins et en viennent a se completer dans le cadre du TALN. La difference entre les deux grammaires est representee dans cet exemple extrait de [Candito & al., 2009], ou a droite nous trouvons le resultat d’une analyse par constituants et a gauche celui de l’analyse par dependances.  Arbre de constituants puis graphes de dependances Grammaire de constituantsA l’origine issue des theories du distributionnalisme (Blommfield, Z. Harris), l’analyse syntaxique par grammaire de constituants est par ailleurs fortement inspiree des theories generativistes de Noam Chomsky. [Aubin, 2002] et [Candito & al., 2009] Les bases posees par Bloomfield dans les annees 1930 precisent la notion du constituant immediat et une distribution “simple” (d’ou le terme distributionalisme) des elements dans la structure de la phrase. Bloomfield propose des regles de base de type :
Ces regles seront augmentees par Z. Harris qui apporte la notion de transformation de phrases complexes en equivalent phrases simples. Chomsky quant a lui est a l’origine de la grammaire generative (annees 60) et de la theorie X-Barre (fin 70) ou apparaissent les notions d’universaux de langage, de structures grammaticales beaucoup plus complexes avec un degre de semantique ou certains constituants gouvernent d’autres, etc. L’interet de l’analyse syntaxique par constituants est qu’elle permet d’exprimer des « generalisations structurales evidentes » [Candito & al., 2009]. La representation se fait par arbre syntaxique, la plupart ont recours aux grammaires hors-contexte avec l’usage d’un vocabulaire terminal (lexique) et d’un vocabulaire non-terminal (categories syntaxiques). Grammaire de dependancesTesniere et Mel’cuk sont a l’origine des theories d’analyse syntaxique par grammaires de dependances. La grammaire de dependances est fondee sur le principe qu’un mot depend d’un autre dans une phrase. Par exemple, les traits morphologiques de type pluriel creent des dependances morphologiques entre deux unites lexicales. La syntaxe est alors organisee a partir des fonctions de mots et non plus de leur categorie. En outre, la grammaire de dependance est basee sur un dictionnaire dans lequel la valence (nombre et type d’argument : actant ou agent, actant ou theme, outils, lieu, etc que prend un verbe) est necessairement explicitee. Lucien Tesniere, dans la 1ere moitie du XXᵉ siecle, developpe la grammaire et la terminologie connexe. Apparaissent certaines notions majeures :
Mel’cuk, fin XXᵉ, debut XXIᵉ, s’inspire des travaux de Tesniere et de Chomsky et propose la Theorie sens-texte (TST ou MST, modele sens-texte), theorie souvent citee dans les modules de TAL. La TST de Mel’cuk considere differents niveaux d’analyse avec la representation de multiples composantes de la linguistique : la phonologie, la phonetique, la morphologie, la syntaxe et la semantique qui equivalent aux differents niveaux de modelisation d’un enonce. Elle schematise ainsi les relations entre les composantes : 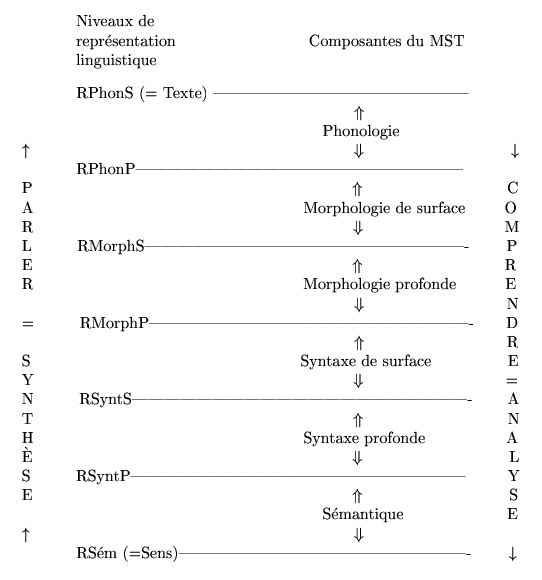 Theorie Sens-Texte de Mel'cuk Deux structures possibles :
La representation des enonces prend la forme d’un graphe ou les n?uds sont des unites lexicales dont les dependances sont exprimees par des arcs. L’annotation en dependance peut se faire directement ou a partir des etiquettes fournies par l’analyse en constituants. Il n’y a pas, selon [Candito & al., 2009], de comparatif avec ou sans analyse par constituants au prealable. Enfin, il existe differents schemas d’annotation en dependance eux-memes relatifs aux differentes theories d’annotations existantes : EASy, GR (standard international), Stanford Dependencies (standard international) ou encore PARC (standard international). L’interet croissant pour ces theories en TAL est assez bien represente dans la litterature scientifique. Ils permettent en effet une extraction plus directe de la structure argumentale et fournissent un langage plus neutre pour l’evaluation. La structure argumentale permet de se representer la position du sujet agissant, de celui qui subit, du lieu, etc. dans une phrase. Elle peut etre utile dans le cadre de l’extraction d’informations au sujet d’evenement par exemple : date, lieu, acteur, objet, instrument, etc. Ce type d’analyse peut egalement aider a la resolution d’anaphore pour savoir ce a quoi renvoie les pronoms referents, les termes de type en dans “il en a achete, etc. Les analyseurs les plus connus pour le francais semblent etre le Berckley Parseur, le MST Parseur ou MaltParseur cites precedemment. Sous ce lien, il est possible de les telecharger et d’y trouver une evaluation de Marie Candito. ConclusionEn conclusion de ces trois points presentes, nous comprenons qu’il y a differents niveaux de granularite dans l’analyse linguistique, en l’occurrence syntaxique, automatiquement etablie sur corpus. Simple ou complexe, chaque type d’analyse presente un interet et c’est l’information a exploiter qui determinera le choix des outils. Plus l’outil sera complexe plus nous nous rapprochons de l’intelligence artificielle ou le processus est apte a se representer et a comprendre le langage naturel pour en extraire des informations precises, pour les interpreter ou encore pour exprimer une reponse appropriee. Ressources
zp8497586rq
Watch now: Writing A Persuasive Essay
Mots clefs : analyse morpho-syntaxique, analyse syntaxique, grammaire de constituants, grammaire de dépendances, syntaxe, TALN |