Blog Onyme
Les ontologies informatiques : l'exemple par OWL et autres5 juillet 2011Suite à la publication d'un premier billet présentant le concept général d'ontologie, nous nous intéressons désormais à son existence concrète en tant qu'outil informatique. Les standards : RDF, XML et RDFSLes triplets RDFRDF, abréviation de Ressource description Framework, est à concevoir comme un modèle de représentation. Il est à la base de la logique de représentation et de structuration des savoirs. Ces derniers s'organisent autour de plusieurs graphes, collections de triplets dans lesquels chaque élément de connaissance se présente sous la forme : sujet, prédicat, objet. 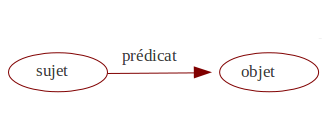 Représentation schématique courante du triplet RDF  Exemple de triplet RDF Le RDF n'est pas (malgré certaines confusions rencontrées) directement associé au XML. Il sert de modèle, pose les principes de structuration pour des schémas appelés aussi vocabulaires. Certains de ces schémas sont proposés et/ou validés par le Word Wide Web Consortium (W3C) : OWL, SKOS, etc. Certains sont indépendants : FOAF, etc. Nous y reviendrons. En outre, le RDF est fondé sur la notion d'URI, adresse locale ou distante des ressources. Les objets et les prédicats sont associés aux URI, les objets peuvent également l'être. Syntaxe XMLLe XML (eXtensible Markup Language) est une syntaxe de description, langage informatique conçu pour structurer et partager les données. Le XML répond à certains principes rigoureux dont la validation nécessite le plus souvent une DTD ou autre schéma de description. Le XML doit surtout répondre à une logique structurelle, une rigueur syntaxique, mais également à une logique informationnelle, une rigueur dans la formulation (ce qui lui donne ce degré sémantique). Exemple d'une structure xml sans schéma associé : 21 266 Programming the semantic Web RDF/XMLAppuyé sur la syntaxe du XML, le RDF offre une logique de structuration des savoirs. On parle alors de RDF/XML. Exprimé dans ce langage, la structure précédemment prise pour exemple pourrait rendre compte des relations entre les différents éléments en définissant des sujets, des objets et des prédicats. Par exemple : Programming the semantic web est un titre ; un titre se donne à un ouvrage ; un ouvrage a un certain nombre de pages ; un éditeur édite un ouvrage; etc. Une succession de triplet permettant d'inférer automatiquement des raisonnements de type : Programming the semantic web est un ouvrage de 266 pages édité par O'Reilly. RDF SchémaRDF Schéma est le vocabulaire de structuration proposé pour la description du savoir. Répandu aussi sous l'acronyme RDFS, il répond aux principes du RDF (collection de triplets organisés en graphes) et propose des noms de balises et attributs XML standardisés (tant dans leur forme que dans leur organisation) pour l'échange et le partage des données décrivant les savoirs. Ces trois aspects fondamentaux du web sémantique sont quelque peu complexes (et non exhaustifs… nous aurions pu également aborder N3, N-Triple, Turtle, RDFa, etc.). Ce pourquoi il semble intéressant de faire une redirection vers un diaporama assez clair sur le sujet, proposé par Les Petites Cases et disponible sur SlideShare. Quelques schémas existantsIl y a donc des schémas standardisés pour une fonction précise et qui répondent aux précédents principes exposés. Il y a par ailleurs des exemples d'implémentation de ces schémas partagés par des communautés (puisque tel est l'objectif). Ci-dessous une brève présentation de quelques schémas pour l'exemple. Web Ontology language (OWL)Schéma de description standardisé par le W3C, le OWL est un vocabulaire poussé décrivant les savoirs. Au-delà d'une hiérarchie, OWL offre des possibilités très affinées d'inférence et de raisonnement permettant ainsi la manipulation d'ontologie. Très complexe, sa structure prend trois formes, de la plus simple à la plus complexe : OWL Lite, OWL DL et OWL Full qui diffèrent par quelques principes de structuration mais qui restent compatibles. La version Full sert à décrire et à inférer de la manière la plus complexe possible, se voulant au plus proche des raisonnements humains. La version simplifiée ainsi que l'intermédiaire permettent de répondre à plusieurs degrés d'attentes dans la définition de l'ontologie (selon les besoins, les objectifs et les moyens). OWL se présente sous la forme de classes, de propriétés et d'instances. Une classe comprend une collection de propriétés et décrit un ensemble d'instances. À savoir que toutes les ontologies en OWL ont une “super classe” appelée Thing dont toutes les autres classes sont des sous-classes. Soumises au principe de subsomption, les classes héritent des propriétés des classes qui les dominent. Les propriétés font la richesse du schéma. Elles permettent d'associer des domaines, de restreindre ces associations, de définir des types de données, de définir des raisonnements logiques, etc. Elles peuvent être hiérarchisées et caractérisées (par exemple si elles sont symétriques (si un individu est lié à un autre par une propriété alors le second est également lié au premier par cette même propriété : si A estFrère de B alors B estFrère de A) Les instances de classes, appelés aussi axiomes sont les membres de ces ensembles. En d'autres termes, ce sont les objets des domaines. Elles sont définies par leur appartenance à une classe et des propriétés. Ces dernières permettent à la fois d'associer les individus (owl:sameAs permet d'associer Charlie Parker et The Bird) mais également de typer les données auxquelles doivent correspondre les individus (une date d'album correspond à un format particulier de date). SKOSSimple Knowledge Organization System (ou Système simple d'organisation des connaissances) est un modèle de structuration adapté aux données terminologiques structurées types thesaurus, vocabulaires contrôlés, classification ou encore les tags issus de la folksonomie (tag, descriptions de contenu par les utilisateurs). Un exemple est visible sur le site de bibliothèque du Congrès qui a traduit son langage d'indexation LSCH en SKOS. L'autorité web semantics illustre la forme et ce qu'il est possible de faire avec SKOS.
Dubin CoreAutre schéma très utilisé dans le domaine des sciences de l'information, le Dublin Core est un schéma de description de données bibliographiques pour des ressources documentaires numériques ou non : site Internet, monographie, blog, eBook, etc. Il permet l'échange de description bibliographiques pour les bibliothèques par exemple. DCMI Metadata Terms in the /terms/ namespace 2010-10-11 L'utilisation cumulée de SKOS et du DublinCore est donc une solution assez intéressante pour la description de ressources bibliographiques. C'est pourquoi, si nous reprenons l'exemple de la bibliothèque du Congrès, nous remarquons qu'elle utilise ces deux schémas dans sa définition de Web sémantique 2000-04-28T00:00:00-04:00 2001-10-01T09:56:06-04:00 L'objet “web sémantique” est donc ici définit en RDF, associé aux autres objets de la terminologie du thesaurus de la LSCH par le SKOS et l'ensemble de cette définition est elle-même associée à des métadonnées présentées en DublinCore. FOAFFriend-of-a-Friend est un modèle de structuration des données sur les personnes dont les spécifications se retrouvent sur cette page. Il permet de structurer des données sur les individus, de les partager et surtout de faire des liens entre ces données. À l'heure du web social son intérêt est donc croissant. Marina Soler Melle Marina Soler Mumasiquery 8778033c8713243356fa6190ca32673658e10c78 Des descriptions FOAF sont en ligne. Pour les trouver, une recherche de type “foaf.rdf” permet d'accéder à des exemples assez bien fournis. Nous pouvons à nouveau remarquer sur ces pages l'utilisation récurrente du Dublin Core et autres vocabulaires de description (par exemple). ConclusionEn conclusion nous pouvons confirmer que le monde des ontologies informatiques présente deux problématiques interdépendantes : la forme et le fond, la logique structurelle et informationnelle. l'objectif étant, sur un domaine général ou spécifique, pouvoir établir des relations de manière automatisée entre deux éléments du réel. —– sources non citées dans l'article
zp8497586rq
Mots clefs : Dublin Core, FOAF, ontologie, OWL, RDF, SKOS, XML |
Wow! This could be one particular of the most useful blogs We’ve ever arrive across on this subject.Basically Magnificent.I am also an expert in this topic therefore I can understand your effort
Thanks for your comment, very encouraging ! It’s a large topic, difficult to be exhaustiv…