Blog Onyme
La R&D pilotée par les tests avec TestNG21 décembre 2010Dans un précédent billet, nous vous présentions notre démarche de R&D pilotée par les tests qui consiste à évaluer en continu les différents prototypes ou algorithmes mis au point pendant un projet de R&D. Dans ce billet nous allons utiliser un cas client pour illustrer la démarche et présenter les outils que nous avons utilisé. Le cadre du projet est l’amélioration de l’agent conversationnel (ou bot) développé par un client. Parmis les différents points, il y a celui d’améliorer sa capacité à reconnaître et classer les messages de type “interaction sociale”. Voici un exemple d’interactions sociales simples :
Nous avons notamment en charge le développement d’un composant qui reçoit en entrée une phrase et qui fournit en sortie une liste de catégories (si le message est bien une interaction sociale). Le format de sortie est une liste d’objets de type SocialInteraction : Voila pour le contexte. Besoins
*L’ensemble du projet comporte une dizaine de composants à évaluer À partir des points 3., 4. et 5. on pense rapidement aux tests unitaires, JUnit et la génération de rapports HTML … Seulement, pour l’avoir employé dans un précédent projet à des fin d’évaluation, il s’avère encore complexe d’utiliser JUnit dans le cadre d’exécution suivant :
TestNG : le framework de tests next generationTestNG est un framework de tests sembable à JUnit, qui est né pour palier à certaines limites de ce dernier. Parmis les fonctionnalités intéressantes de TestNG, nous avons trouvé :
Avec toutes ces fonctionnalités nous possédons presque l’outillage nécessaire pour réaliser l’évaluation de notre composant de classification. Gestion de l’indicateurF-MesureNous avons choisi la formule F-Mesure car elle reflète bien l’écart entre le résultat produit et le résultat attendu en intégrant les notions de précision (P) et rappel (R).
Intégration de la F-Mesure dans les tests TestNGBien qu’étant souple et extensible, TestNG est un framework de tests unitaires. A l’instar de JUnit il fonctionne avec des Assertions. Or une assertion est soit vraie, soit fausse. Mais ne peut en aucun cas être à 50% vraie… L’astuce que nous employons est de considérer qu’une F-Mesure < à 1 fait échouer l’assertion évaluant l’égalité entre le résultat attendu et le résultat produit, et surcharger le modèle java des AssertionError pour pouvoir enregistrer notre score afin de l’afficher dans le rapport : package evaluator;
/**
* An assertion error that hold a score
* @author tvibes
*/
public class AssertionScoreError extends AssertionError {
private double score = 0.0;
public AssertionScoreError(Object detailMessage, double score) {
super("" + detailMessage);
if (detailMessage instanceof Throwable)
initCause((Throwable) detailMessage);
this.score = score;
}
public double getScore() { return this.score; }
}
Il ne reste qu’a créer une méthode assertScore() qui va nous permettre de lever nos AssertionScoreError : package evaluator;
/**
* @author tvibes
*/
public class ExtendedAssert {
public static void fail(double score){
fail(null, score);
}
public static void fail(String message, double score){
throw new AssertionScoreError(message == null ? "" : message, score);
}
static public void assertScore(String message, double score){
if(score<1)
fail(message, score);
}
}
Les méthodes @DataProvider : “alimenter” nos méthodes de tests en données.Plus simple à manipuler que l’équivalent JUnit @Parameters, c’est véritablement la fonctionnalité qu’il nous fallait pour pouvoir jouer notre test de composant sur un corpus de test. Le Data Provider est une méthode package evaluator.unit.testng;
import static evaluator.ExtendedAssert.assertScore;
import java.util.ArrayList;
import java.util.List;
import org.testng.annotations.Test;
import evaluator.dataproviders.SocialDataProvider;
import evaluator.scoring.IScoringService;
import ac.search.SocialSearcher;
import ac.output.SocialInteraction;
/**
* @author tvibes
*/
@Test(suiteName="Tests unitaires", testName="Classification")
public class ClassificationTest {
IScoringService<List<SocialInteraction>> scoringService = null;
public ClassificationTest(){
scoringService = new evaluator.scoring.FMeasureSocialInteractionService();
}
/**
* Test method for "message classification"
* @param testMessage
* A test message
* @param classes
* A list with the expected business objects (SocialInteraction)
*/
@Test(dataProvider="createSocialMessage")
public void testClassificationNG(String testMessage, List<SocialInteraction> classes){
SocialSearcher searcher = new SocialSearcher();
List<SocialInteraction> current = searcher.getSocialResults(testMessage);
double score = scoringService.calculate(current, classes);
assertScore("Résultat: " + current.toString(), score);
}
@DataProvider(name="createSocialMessage")
public static Object[][] createSocialMessage(){
Object[][] corpus = new Object[][]{
{"Bonjour", new SocialInteraction(SocialInteraction.OUVERTURE, 100)},
{"Au revoir", new SocialInteraction(SocialInteraction.FERMETURE, 100)},
};
}
}
Dans cet exemple, la méthode data provider fourni un corpus contenant 2 phrases avec le résultat attendu. Gestion des corpus de testsPour des questions pratiques, nous stockons le corpus de test dans une base de données dont voici le modèle physique : 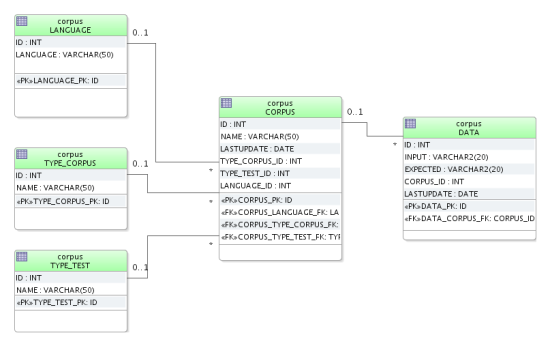 Modèle physique pour le stockage du corpus de test La table DATA est la plus importante : c’est elle qui contient les verbatims ainsi que les résultats attendus. Les résultats attendus (colonne expected) sont des objets que le module TAL est censés produire. Pour l’accès au corpus de tests, nous ajoutons quelques librairies bien utiles :
ReportingReportNGUn des points noirs pour notre projet dans les briques rassemblées jusqu’ici est la génération de rapport par TestNG : les rapports sont vraiment moches (J’espère que Cédric Beust me pardonnera, si un jour il lit ce billet). Heureusement, l’extensibilité du framework (existence d’une API de reporting) a fait que des développeurs ont mis au point des modules de génération de rapports beaucoup plus esthétiques. C’est le cas de Dan Dyer qui propose le plug-in ReportNG ReportNG est disponible dans le repository Maven ou sur Github. A la base ReportNG prévoit la possibilité de surcharger la feuille de style. C’est bien, mais insuffisant pour nous : Nous avons besoin de modifier les pages pour y faire apparaître nos indicateurs. ReportNG utilise le moteur de template Velocity.
 Exemple de rapport - l'évaluation de nombreux composants est présentée Grâce à quelques helpers que nous déclarons dans le contexte Velocity, nous pouvons mettre en forme notre rapport de synthèse qui agrège les scores de l’ensemble des tests. Les différents résultats sont “colorés” de manière à identifier rapidement les séries de tests qui donnent de bons résultats ou ceux qui en donnent de mauvais et sur lesquels nous allons devoir travailler! (exemple: vert = score > à 80%; rouge sombre = score < à 20%) maven-site-pluginCe plug-in pour Maven permet d’ajouter des pages de documentation ou d’analyse à nos rapports. Je ne vais pas détailler cette partie, la documentation du plug-in permet de rapidement comprendre comment générer un “maven site” et y intégrer les rapports produits par ReportNG. ConclusionDans notre précédent billet, nous tentions de démontrer à quel point l’évaluation continue des résultats est importante dans un projet R&D. Avec TestNG, nous disposons de l’outil permettant de concrétiser cette démarche d’évaluation sans avoir passé trop de temps sur la mise au point. Il s’intègre bien à Maven et nous pourrions aller jusqu’à déclencher l’évaluation à chaque commit dans les composants de traitement, sur notre serveur Hudson et regénérer les rapports. Par ailleurs, cet ensemble pourra être réutilisé dans nos autres projets. Il ne nous suffira plus que :
|

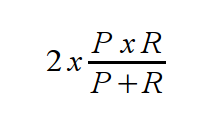 Le résultat est un nombre entre 0 et 1, résultat qu’il est donc facile de convertir un pourcentages.
Le résultat est un nombre entre 0 et 1, résultat qu’il est donc facile de convertir un pourcentages.
Oui, je suis bien conscient que les rapports HTML par défaut sont plutôt laids, j’espère y remédier bientôt
Petite précision: la méthode @DataProvider n’a pas besoin d’être statique.
Merci pour la “coquille”, j’ai corrigé.
Nous “suivrons” les évolutions de TestNG avec attention si les rapports doivent évoluer.
En tout cas c’est gentil de passer par ici