Blog Onyme
Apprentissage artificiel : Fondements et protocoles pour la classification et les regroupements26 avril 2012IntroductionUn sujet que je n’ai encore que peu abordé dans ce blog concerne la notion d’apprentissage artificiel (que l’on désigne également par apprentissage automatique). C’est pourquoi, je vous propose une série de billets traitant de cette problématique. Nous étudierons principalement les tâches de classification et regroupement car elles sont au cœur de nos préoccupations.
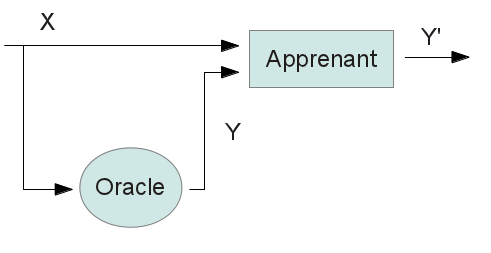
Ce premier billet va nous servir à introduire les premières notions indispensables pour comprendre le domaine, le but recherché et les étapes principales de sa résolution. Fondements de l’apprentissage artificielClarifions d’abord les fondements de l’apprentissage artificiel. Pour cela, il faut repartir des origines de l’intelligence artificielle. L’intelligence artificielle vise à faire réaliser par des machines des tâches complexes normalement abordables uniquement par des humains. L’approche classique consiste à étudier la tâche à réaliser et à développer le programme “intelligent” qui va pouvoir l’accomplir (dans l’idéal bien sûr). Un problème qui peut être induit par cette démarche est le coût engendré par l’étude de chacune des tâches et la conception d’algorithmes uniques pour chacune d’elles. Alors comment résoudre ce problème? La solution imaginée consiste à remonter l’intelligence artificielle à un niveau supérieur. Plutôt que d’étudier les tâches individuellement et de développer un programme intelligent pour chacune d’elles, l’étude porte sur un ensemble de tâches “similaires”. Le but du programme intelligent est alors d’observer les caractéristiques spécifiques de chacune des tâches pour s’adapter à leurs résolutions. L’intelligence artificielle n’est alors plus concrètement au niveau de la réalisation de la tâche mais au niveau de l’auto adaptation du programme ciblée sur la réalisation de la tâche. Cette philosophie porte le nom d’apprentissage artificiel. Protocoles d’apprentissage en classification et regroupement : de l’apprentissage naturel à l’artificielUn algorithme d’apprentissage artificiel permet donc l’adaptation automatique à la réalisation d’une tâche appartenant à une catégorie de tâches similaires. Cette notion de catégorie de tâches est importante car chaque algorithme d’apprentissage est connu pour fonctionner sur certains types de tâches et pas sur d’autres. Il est donc nécessaire de déterminer quelles sont les algorithmes à employer en fonction du type de la tâche. Parmi ces types de tâches, nous trouvons celles de classification et regroupement de textes que nous étudions plus en détails ici. Pour mieux comprendre le principe de l’apprentissage artificiel, nous allons établir quelques parallèles avec l’apprentissage naturel qui diffère de l’artificiel par le fait qu’il soit réalisé non pas par une machine mais par un humain. Imaginons que nous (humain) souhaitions apprendre à faire une tâche de classification/regroupement qui nous est totalement inconnue de prime abord. Par exemple classer (ou regrouper) des revues par thème. Bon d’accord, vous savez probablement déjà le faire mais bon j’ai dit imaginons…. Comment nous y prendrions nous pour apprendre à le faire sans connaissance particulière au préalable? Nous avons déjà en partie répondu à cette question en énonçant ce qu’était un apprentissage. La clé est dans l’observation des caractéristiques de la tâche à accomplir. Mais concrètement comment cela se traduit-il? Si nous sommes seul pour réaliser cette tâche, nous pourrions lire les revues et essayer de découvrir dans leur contenu des points de similitude ou au contraire des points de divergence entre elles. Grâce à cela, nous pourrions alors trouver une façon de regrouper nos revues par thème. Si au contraire nous sommes accompagné d’un éminent professeur spécialiste du classement de revues, nous pourrions alors lui demander de nous indiquer les différentes thématiques de revues ainsi que de nous donner les exemples les plus usuels. Nous pourrions alors en déduire des règles pour nous permettre par la suite de classer par nous même les revues. Notre expert pourrait également ne pas avoir beaucoup de temps à nous consacrer (il est pas mal demandé!). Dans ce cas, nous serions obligé de nous contenter que de quelques exemples délivrés par notre savant professeur et nous serions alors obligé de chercher par nous même les éléments qu’il n’auraient pas eu le temps de nous transmettre. Cet exemple humoristique illustre trois processus d’apprentissage naturel de classification/regroupement. Si l’on souhaite faire réaliser ces mêmes processus à une machine, l’apprentissage devient alors artificiel. Le terme d’apprenant désigne alors le système “qui doit apprendre la tâche”. Comme nous, la machine peut être confrontée à des apprentissages où elle doit apprendre seule ou au contraire avec l’aide d’un professeur (on l’appelle plus couramment Oracle en apprentissage artificiel). Il existe de ce fait trois grands axes de protocoles d’apprentissage artificiel utilisés pour les tâches de classification et de regroupement :
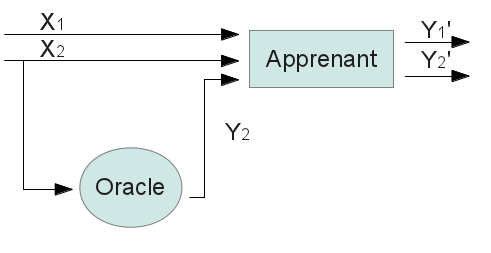
Il existe d’autres types de protocoles d’apprentissage artificiel utilisés pour d’autres types de tâches comme par exemple l’apprentissage par renforcement utilisé entre autres dans la robotique. Nous ne les aborderons cependant pas en détails dans ce billet. Les phases des protocoles d’apprentissage artificiel en classification et regroupementComme notre exemple de classer des revues nous le laissait transparaître, un protocole d’apprentissage artificiel se déroule en phases différentes selon les conditions dans lesquels on apprend. L’apprentissage non supervisé n’en comporte qu’une seule puisque l’apprenant découvre directement la tâche de regroupement depuis les données. Cette phase est appelée regroupement, même si elle est plus connue sous sa dénomination anglaise clustering. Dans l’exemple ci-dessous, les trois données X1, X2 et X3 sont regroupées dans deux groupes distincts regroupant X1 et X2 dans Y1 et X3 seul dans Y2. Les algorithmes supervisés en comportent deux distinctes :
Ces deux phases peuvent être exécutée de manières consécutive ou itérative. Concrètement, il est en fait possible de revenir à la phase d’apprentissage après le début de la phase de classification. On obtient alors une sorte d’itération entre les deux phases visant à perfectionner l’apprentissage au fil de l’eau que de nouveaux exemples sont disponibles. Cela amène alors à différencier deux sous types de protocoles d’apprentissage pour la supervision :
Les algorithmes semi-supervisés fonctionnent sur les deux même phases mais acceptent en plus des données non étiquetées pendant la phase d’entraînement. ConclusionNous abordons dans le prochain billet la question des moyens d’apprendre pour la classification et les regroupements (biais et modèles). Mots clefs : apprentissage artificiel, apprentissage automatique, apprentissage naturel, apprentissage non supervisé, apprentissage semi supervisé, apprentissage supervisé, classification, classification et regroupement de textes, fondements de l'apprentissage artificiel, intelligence artificielle, protocoles d'apprentissage artificiel, regroupement |